This process describes our transport retry strategy to provide you with context for your design.
On 1 October 2025, we’ll launch the new Service Providers website. All users will be required to log in with a Chorus managed account, and old URLs will automatically redirect to the new site. Learn more.

This process describes our transport retry strategy to provide you with context for your design.
Our design allows for messages to be resent automatically during an HTTP network failure. The following diagram provides an overview of the HTTP Application layer retry process
The retry function is set to:
If your system responds with a 5xx error rather than an acknowledgement we will only attempt to deliver the message once during each retry scenario. “Note that the retry time, in this case, can be less than 15 minutes if we receive another trigger into our datastore (a response to a request from you).
If your system is unresponsive and provides no response we will time out waiting for your response after 10 seconds and we will attempt to deliver the message 3 times during each retry scenario. The first message that is successfully acknowledged changes the status of your endpoint to available and we will attempt to retry the remaining messages.
Unsent messages are persisted using a data store, this guarantees that they are saved even if a server is restarted.
If you send an acknowledgement with 'LFC001' in the soap error code field we will remove the message from the queue (either response to sequential).
CreateOrderResponse, AmendOrderNotification, InformOrderNotification, CreateOrderNotification are the messages on Sequential Queue.
If the Max delivery attempt count is exhausted, the message will be placed at the head of the queue. The maximum time will be a 15-minute delay before the message delivery retry is restarted. Whether the maximum delay occurs will depend on what the failure was that caused the delivery attempts to fail – see above for details.
This cycle continues until the message is delivered. It ensures that messages are sent in the sequence they are generated.
QueryPlaceResponse, QueryProductOfferInformationResponse, QuerySiteInformationResponse, QueryOrderFeasibilityResponse, QueryAppointmentResponse, ReserveAppointmentResponse, QueryOrderResponse, AmendOrderResponse, CancelOrderResponse are the messages on Response Queue.
This queue is for messages where the most recent is considered the most important when the timer retries it will attempt any new messages first before retrying the message that did not receive a valid acknowledgement.
The following order is observed when we place messages on to the Response queue:
e.g., A received state priority 1 message should be selected prior to an errored state priority 2 message, where 2 has a higher priority than 1.
Any QueryPlaceResponse, QueryProductOfferInformationResponse, QuerySiteInformationResponse, QueryOrderFeasibilityResponse, QueryAppointmentResponse, ReserveAppointmentResponse, QueryOrderResponse message that fails to be acknowledged after 3 sets of retries will be marked as failed and not retried again.
This queue has 5 concurrent threads per RSP, so messages can be sent in parallel as the order of message delivery is not critical.
Where all attempts are failing the queue is marked as down and will only make reattempts of the message [refer above] until a successful acknowledgement – it will then resume normal processing of messages.
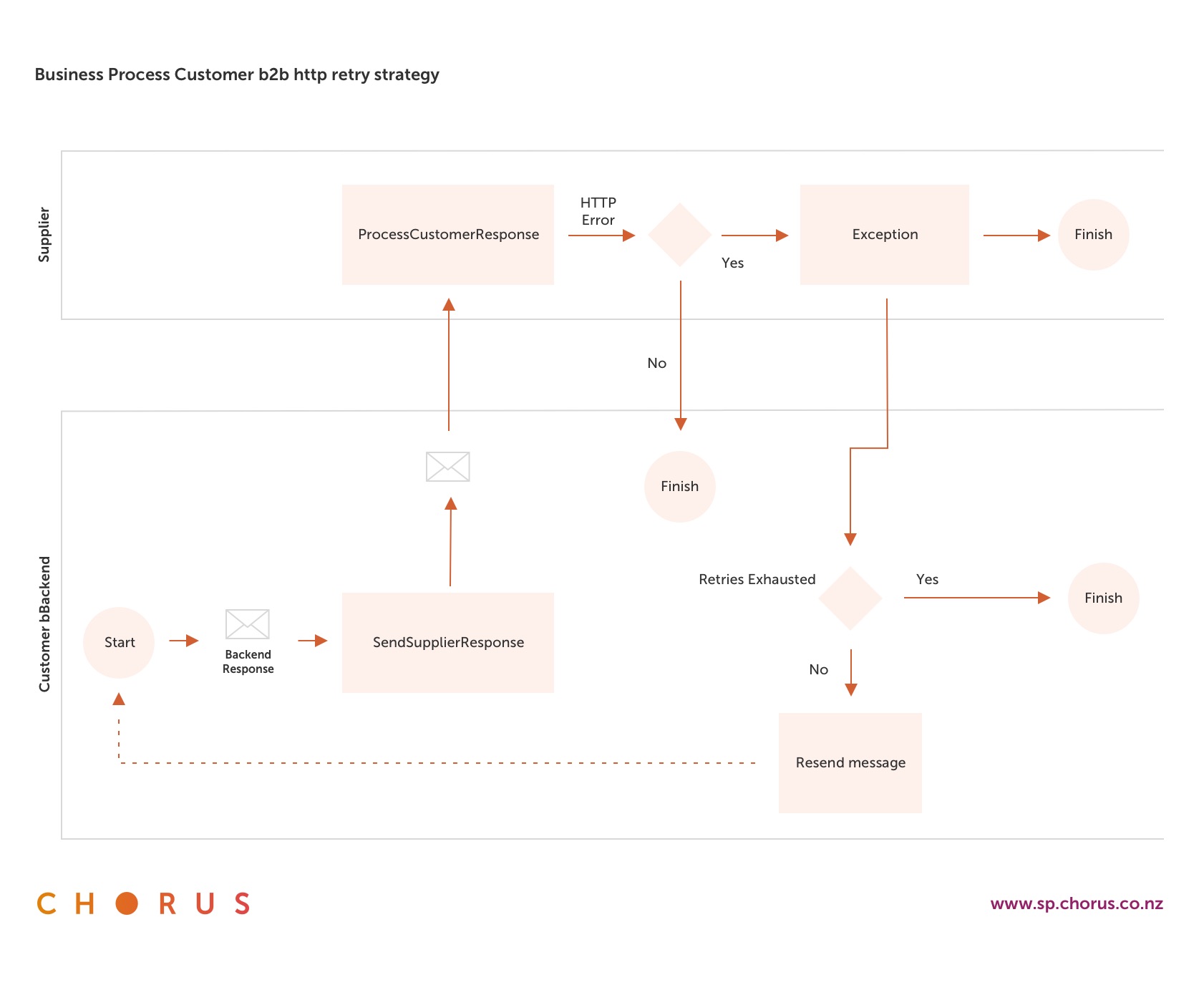
The customer retry strategy is provided to give insight into resending of messages automatically in the case of a network failure on our side. The following diagram provides an overview of a customer HTTP Application layer retry process.
This is an indicative representation of a retry process at the transport level. The way you implement your retry process will not affect us and is solely your responsibility. We recommend that you consult your HTTP library implementations for the default behaviour to understand its configuration capabilities for use when communicating over HTTP.